这篇文章上次修改于 3005 天前,可能其部分内容已经发生变化,如有疑问可询问作者。 通常来说,在我们的系统中会把数据永久保存在DB中,并且冗余一份数据在缓存中。读请求优先从缓存读取数据,没有再从DB读取,如下图: 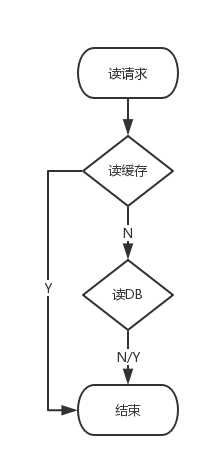 好处是可以减小DB的压力,提高请求的响应速度。但这种架构在提升系统读请求处理能力的同时,给系统写请求的处理带来了不少的麻烦。因为数据在DB跟缓存中各自保存了一份,如何保证它们之间的数据一致就是本文要讨论的问题。<!--more--> **当处理写请求时有两种方式:** - ##先写缓存再写DB **删缓存->写缓存->写db** 如果第2步写缓存失败,直接返回,无影响。 如果缓存写成功,DB写失败,此时如果不清除缓存中已写入的数据,则会造成数据不一致(缓存中是新值,DB中是旧值)。 ##场景1: 当更新数据时,如更新某玩家积分,当前db的库存是99,现在要更新为100,当缓存更新成功,db写入失败时,这意味着db存的是99,而缓存是100,这导致数据库和缓存不一致。 ##场景2: 在高并发的情况下,如果当写完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存过期,就去数据库里查,以电商秒杀为例,如果数据库中产品的库存是100,现在要更新为99,缓存更新成功,db写入失败时,数据库存的是100,缓存是99,这导致数据库和换成不一致。 - ##先写DB再写缓存 **写DB->删缓存>写缓存** 如果DB写入失败,直接返回,无影响。 如果DB写入成功,缓存无论删除失败还是写入失败都会造成数据不一致(即DB中是新值,缓存中是旧值)。 ##场景: 当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。 上面3种场景中,无论哪种情景,都必须确保删缓存写缓存为原子操作。 #问题分析 上面所说的问题本质上就是一个分布式数据一致性问题,在不要求强一致性的场景下,我们只要开辟一个异步任务去保证最终一致性即可。发生失败时,我们可以开启一个异步线程去做数据回填操作,反复重试直到成功。如果采用异步线程回填数据的方式做最终一致性,那么这个容错性是内存级别的,也就是说如果此时重启服务(线程消失),那么这个重试任务就丢失了,导致数据不一致。 缓存数据设置过期时间就是一种数据最终一致性的方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以DB为准,对缓存操作只是尽最大努力即可。也就是说如果DB写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从DB中读取新值然后回填缓存,完成数据的最终一致性。除此之外,写db之前要做数据一致性校验,如(select ... for update) ##写请求  如上图,每次处理写请求时,将会经过如下几个步骤: 首先针对要写入的数据设置一个状态,失败则结束,成功则转2。 如果设置状态成功,则直接清除缓存,失败则解除状态并结束,成功则转3。 清除缓存后,再写入DB,失败则解除状态并结束,成功则转4。 DB写入成功以后,把新值回填缓存,失败则解除状态并结束,成功则转5。 回填成功,解除状态并结束。 ##读请求  如上图,每次处理读请求时,将会经过如下几个步骤: 直接从缓存读取数据,成功则结束,失败则转2。 从DB读取数据,失败则返回,成功则转3。 根据从DB读取到的数据判断该数据对应的状态,如果没有状态,则回填缓存并结束,如果有状态,则直接结束。 总结来说就是我们通过一个状态把读写请求关联起来,这里先不讨论这个状态的实现细节以及各种容错,比如说解除失败以后怎么处理。 #总结 在大部分场景下,缓存一致性都难以做到强一致性,选择是先写缓存还是先写db需要根据场景来取舍,做到最终一致。缓存数据设置过期时间就是一种数据最终一致性的方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以DB为准,对缓存操作只是尽最大努力即可。也就是说如果DB写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从DB中读取新值然后回填缓存,完成数据的最终一致性。除此之外,配合消费队列,更进一步避免写操作锁冲突问题。
没有评论